Netlify + Cloudflare = Crazy Delicious
At this years NEJS Conf, Netlify's Phil Hawksworth gave a highly entertaining talk about mostly static content as a new normal path. His demo was a great little app that showed the possibilities of mixing static rendering and a dash of just in time functions as a service.
Previously I had not been a big fan of the JAMstack concept, it hadn't clicked for me and seemed very single page app oriented. This demo piqued my interest, so I decided to move cultofthepartyparrot.com over to try out it's automated deployment systems.
It's magic.
Seriously, it's remarkable how well it worked. CotPP has a custom build script and a lot of weird dependencies, and it all built with minimal intervention.
I set the GitHub repo as its source, pointed the build command at my custom script, and let it rip. The first build failed because I messed up the build command name. The second build had a live version for me to view in 50 seconds. That's pretty great for installing all the tools, generating and deploying it. I was hooked.
I promptly pointed over the domain, got SSL issued and considered it done. And did I mention it creates deploys for all PR's? I could finally preview new parrots in situ before a merge. Pretty amazing for a free product.
Uh-oh.
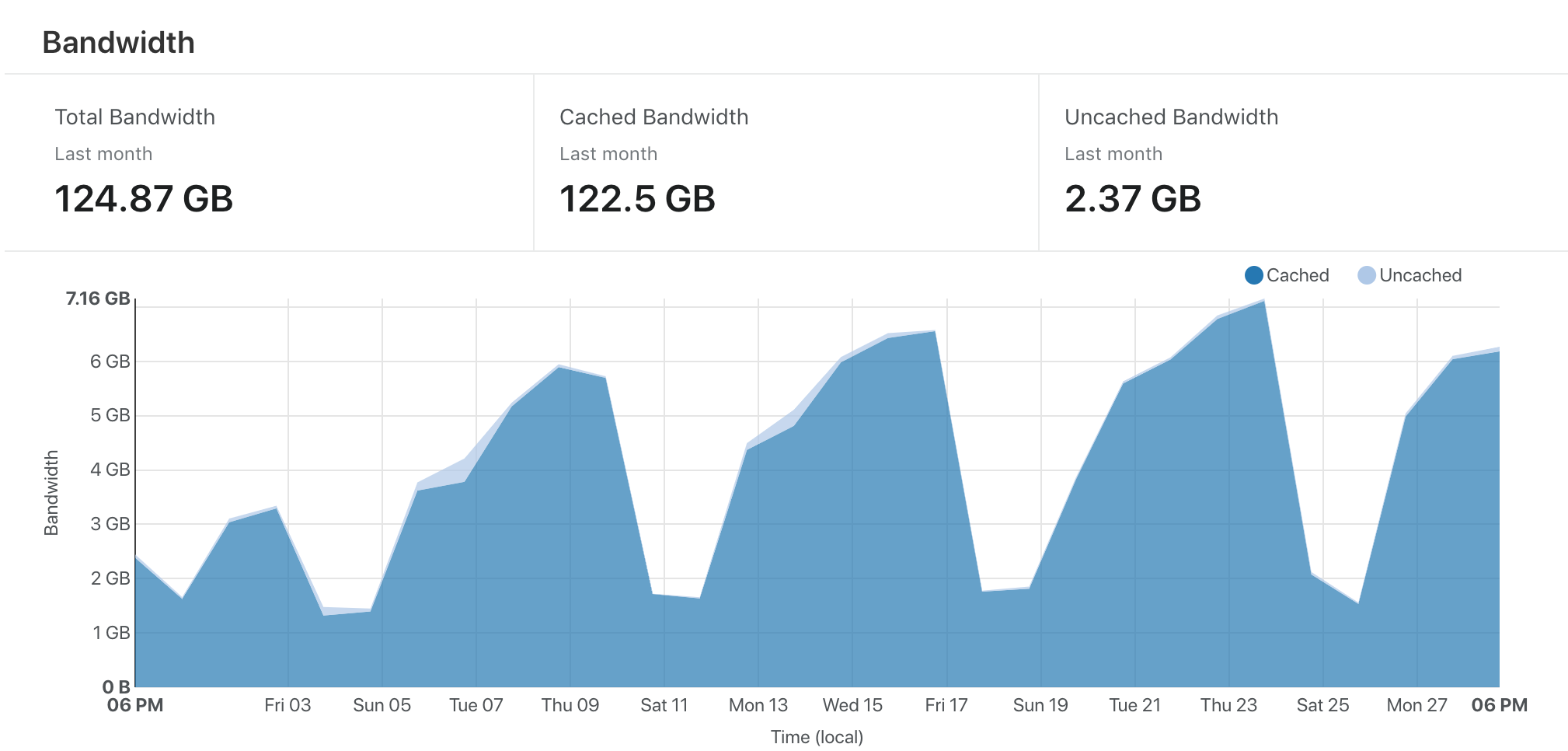
The Cult of the Party Parrot has been hosted on a shared Dreamhost server since its creation. I have Google Analytics on there, so I had some idea of the amount of traffic that it received, but never paid much attention. Turns out, it uses a lot of bandwidth.
CotPP site hit half my free 100GB on @netlify in less than a week. @jmhobbs on Aug 26, 2019
Within five days I had used 50GB of traffic on Netlify. That means I'd be paying ~$60 a month for hosting, which isn't viable for me, as CotPP doesn't have ads or anything. I needed a way to either keep using Netlify, or recreate the Netlify experience (with the PR deploys) in some other toolkit.
My first instinct was to just go back to Dreamhost and figure out the automatic deploys using an existing tool like GCP CloudBuild. But then, the ever reliable and always clever Ben Stevinson suggested that I put Cloudflare in front of it, and speed it up in the process.
That sounded like a good idea to me, if I could get Cloudflare to catch the bulk of the bandwidth, then the 100GB cap of the Netlify free plan should be plenty to host the PR deploys, and I can have the best of both worlds, with the least amount of effort.
Putting Cloudflare in front of Netlify works just fine. I transferred DNS to Cloudflare, and then had it CNAME flatten to the Netlify origin. TLS was easy, and setting up the Cloudflare origin certificate on Netlify was simple too. Finally, I added a page rule that tells the Cloudflare edge to cache everything for a month. Bandwidth problem solved.
But, there was one last issue. Every time Netlify did an automatic deploy for me after I closed a pull request, I would have to manually go in and flush the cache on Cloudflare. That's no good. The solution was to connect a Netlify deploy notification webhook to a GCP cloud function which clears the cache via the Cloudflare API.
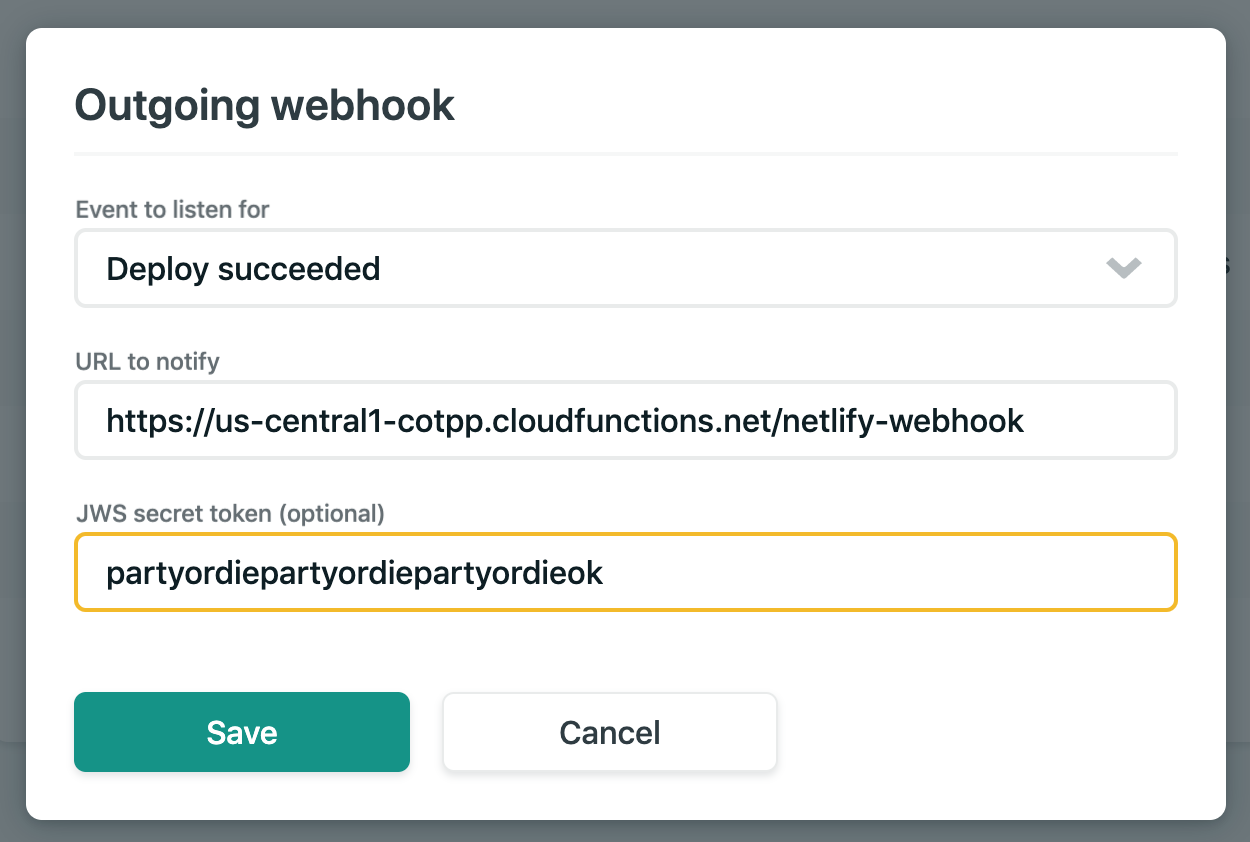
The documentation on the Netlify webhook is a little light, so I ran a few deploys and just printed out the contents to find the keys I need. Here's an abridged example output of what I get in the webhook body.
{
"admin_url": "https://app.netlify.com/sites/cultofthepartyparrot",
"available_functions": [],
"branch": "master",
"build_id": "00000000e8ffde017674b0b2",
"commit_ref": null,
"commit_url": null,
"committer": null,
"context": "production",
"created_at": "2019-08-26T21:04:48.294Z",
...
"updated_at": "2019-08-26T21:05:31.385Z",
"url": "https://cultofthepartyparrot.com",
"user_id": "000000011111112222222333"
}All I really cared about there was branch, and the ID could be useful for tracing deploys to flushes if something went awry. So with that in hand I started putting together my function. The struct for unpacking the webhook is pretty small, and there's nothing novel going on there.
type netlifyWebhook struct {
ID string `json:"id"`
Branch string `json:"branch"`
}
func PurgeCloudFlare(w http.ResponseWriter, r *http.Request) {
var bodyBuf bytes.Buffer
tee := io.TeeReader(r.Body, &bodyBuf)
defer r.Body.Close()
dec := json.NewDecoder(tee)
var wh netlifyWebhook
err := dec.Decode(&wh)
if err != nil {
log.Println("error decoding webhook body:", err)
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}You may note that I used a io.TeeReader there to duplicate the request body reader into a buffer. This is used later when validating the JWT that Netlify sends, more on that later.
Once unpacked, we can check that this update is for the master branch before we proceed. If we flushed on every PR deploy it would be a waste of effort, so we only want to proceed for a merge into master.
if wh.Branch != "master" {
w.WriteHeader(http.StatusOK)
w.Write([]byte("Ok. Thanks."))
return
}Now we want to verify that this request really did originate from Netlify. Now, for this use case it probably doesn't matter that much, who is going to take the time to figure out the details of my cloud function and launch a purging spree to run me out of Netlify bandwidth? But it's easy to implement, and we can learn something along the way, so why not!
jwt := r.Header.Get("X-Webhook-Signature")
if jwt == "" {
http.Error(w, "Forbidden", http.StatusForbidden)
return
}
if !verifyRequest([]byte(jwt), bodyBuf.Bytes()) {
http.Error(w, "Forbidden", http.StatusForbidden)
return
}A Brief Aside About JWT
A JWT is a "JSON Web Token". It's a three part string consisting of a header, a payload and a signature. The header and payload are JSON that is base64 encoded, and the signature is an HMAC of the other two sections, again base64 encoded. The header tells you things about the token itself, such as the algorithm used to create the signature. The payload is arbitrary data, though there are standardized fields, or "claims" in JWT parlance. You can learn more about it at jwt.io, but that should be enough to get us through this
On to the validation!
Since JWT is a well known standard, we have several packages to pick from for validating them. I chose github.com/gbrlsnchs/jwt, which had the API I liked best.
First we need to define the payload we expect from Netlify. Their payload is very simple with just two claims, as their docs say:
We include the following fields in the signature's data section:
- iss: always sent with value netlify, identifying the source of the request
- sha256: the hexadecimal representation of the generated payload's SHA256 docs.netlify.com
type netlifyPayload struct {
ISS string `json:"iss"`
Sha256 string `json:"sha256"`
}Next we send the body of the request, the JWT, and an empty struct to jwt.Verify.
func verifyRequest(token []byte, body []byte) bool {
var pl netlifyPayload
_, err := jwt.Verify(token, hs, &pl, jwt.ValidateHeader)
if err != nil {
return false
}The variable hs here is an instance of an HMAC hashing function, specifically a jwt.HS256, since the Netlify hook always uses that algorithm to sign it's JWTs. That is initialized elsewhere using a secret pulled from the environment.
func init() {
hs = jwt.NewHS256([]byte(os.Getenv("JWT_SECRET")))
}Once the JWT is validated and the payload extracted from it, we hash the contents of the request body with SHA256. Remember that io.TeeReader? This is what we stashed the body for. We compare the hash we derived from the one in the payload to ensure the body was not tampered with in-flight.
h := sha256.New()
h.Write(body)
return pl.Sha256 == fmt.Sprintf("%x", h.Sum(nil))Once everything checks out, we make the request to Cloudflare to purge the whole zone. This is an API method available on all Cloudflare plans, Purge All Files
url := fmt.Sprintf("https://api.cloudflare.com/client/v4/zones/%s/purge_cache", cloudFlareZone)
req, err := http.NewRequest("POST", url, bytes.NewBuffer([]byte(`{"purge_everything":true}`)))
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}
req.Header.Set("Authorization", fmt.Sprintf("Bearer %s", cloudFlareAPIToken))
req.Header.Set("Content-Type", "application/json")
resp, err := cloudflareHTTPClient.Do(req)
if err != nil {
http.Error(w, err.Error(), http.StatusInternalServerError)
return
}Then we're done! We just have to convey the status of the API call as our status to bring it all together.
w.WriteHeader(resp.StatusCode)
if resp.StatusCode != http.StatusOK {
body, _ := ioutil.ReadAll(resp.Body)
log.Println(string(body))
defer resp.Body.Close()
}
}
Overall I'm quite happy with this solution. Perhaps it's a bit over engineered, but it's saving a ton of money I don't have to burn on CotPP, and I don't have to move it back to Dreamhost either.
You can get the full code for this on Github in the CotPP repo on Github.